Experience.Digital chose open source tools like SQLAlchemy and Python to ensure that the migration tool could be repeatable. This meant that anyone could rerun the work exactly as Experience.Digital did, unencumbered by licensing or feature issues.
These are some of the advantages:
- DBAPI wrappers were available for Informix, Db2 and Postgres drivers
- SQLAlchemy relational mappers were available for Db2 and Postgres connections.
- We could control both the schema modification and ETL-style pipeline using the same constructs
- The Alembic migrator provides powerful abstractions and let us generalise schema updates, especially when implementing the temporal and version triggers on the content tables. (more on this below)
- The schema reflection capabilities of SQLAlchemy saved us a significant amount of time of hand crafting schema representations.
We investigated using other technologies, but they were too specialised and required us to use multiple disparate tools. We decided to limit the data type conversions to a single well-understood runtime (Python and Postgres) instead.
We also considered jOOQ, an open source tool that is similar to SQLAlchemy but offers stronger typing by using Java or Kotlin. However, its Informix and Db2 integration are licensed, which made it not a viable option for our project.
Data Processing Pipeline
The solution was implemented using a three-phase approach. The first step was essentially a giant reflection-via-schema-metadata operation. The second step was a convert-and-clone process where we de-serialised Informix and Db2 data types into native Python objects and re-serialised them back into Postgres data types. The third step was a schema merge operation, where we combine three separate databases into a unified final product.
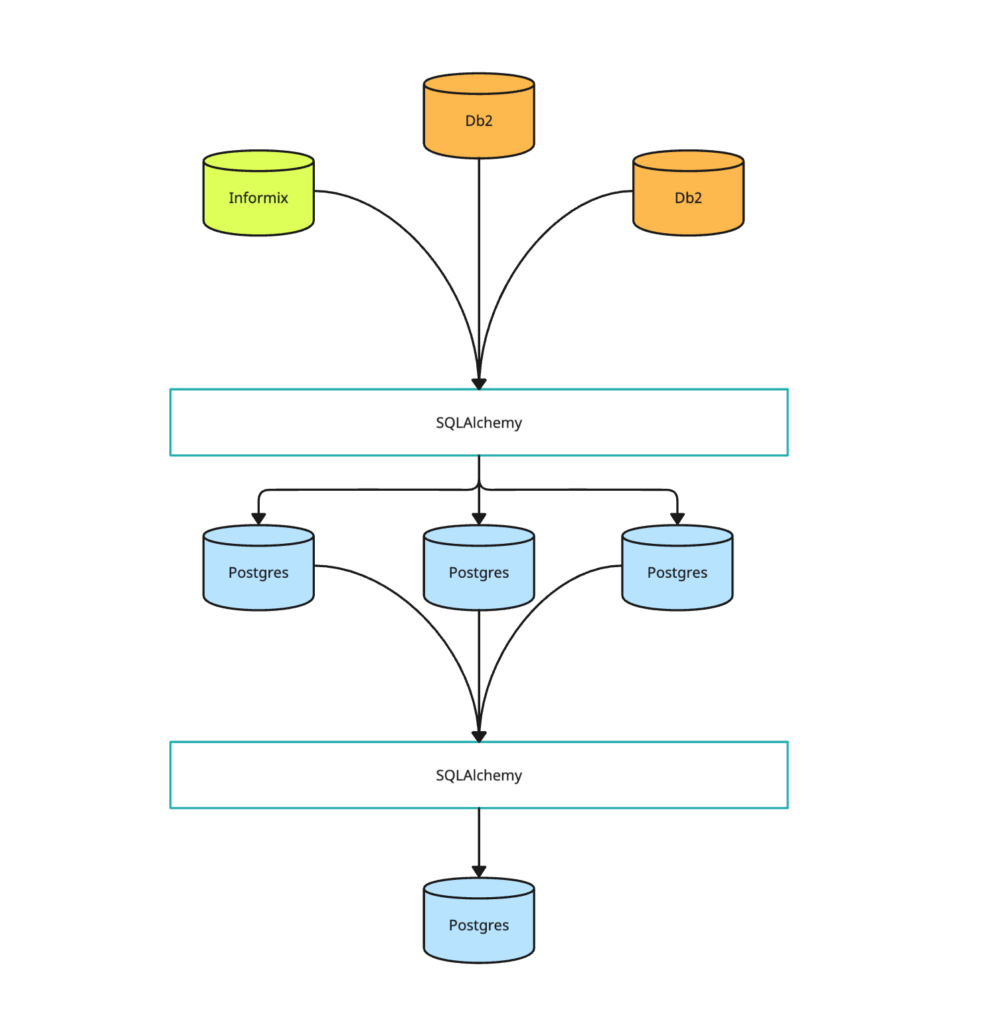
We used an SQLAlchemy layer to develop the solution in a consistent working environment across three different hosts, seven different database instances, and three different database types. This was an invaluable decision, as it allowed us to easily manage the complexity of the project.
Phase 1 – Schema Reflection
We heavily utilised the Alembic migrator for this step. Alembic can generate out mapped python classes that directly correlate to a database it is looking at. It essentially converts reflected schema data into a python class representation.
In this contrived example it looks a bit like this:

Generating 400+ type-compatible classes from an existing database was a lifesaver. We took inspiration from “The Art of Unix Programming” and the “Rule of Generation”:
“Avoid hand-hacking; write programs to write programs when you can. Generated code is almost always cheaper and more reliable than hand-hacked.”
We agree. This is a clear example of how using code to create code can save time and effort.
The second part of the magic trick was using Alembic’s DSL to generate backend-specific schema code from its Python implementation. Alembic had already given us the structure of the tables, so we just switched out its backend implementation and let it do the heavy lifting. The below example shows how we can use a generic Python class with a different Integer type for Informix vs Postgres.
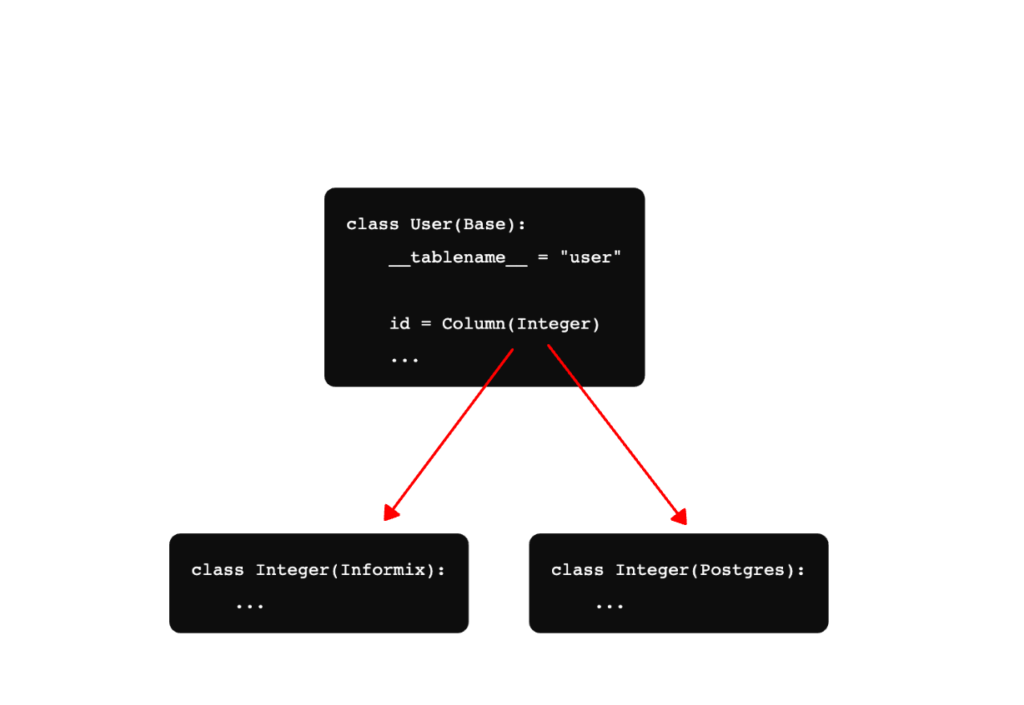
We used Alembic to generate type-compatible migrations for each table in the Informix and Db2 databases. We then applied the migrations to a Postgres database, with a few custom converters for Db2 field types with no 1-1 mapping to Postgres. This resulted in perfect 1-1 schema mapping for all 600 tables across the three databases.
Phase 2 – Convert and Clone
Our initial attempt at data conversion involved accessing the source databases, doing bulk conversion in Python and writing it to the destination. This proved to be ineffective for a variety of reasons, especially as we started getting complaints we were affecting production performance. We also had a particularly frustrating character set issue on one of the Db2 databases that affected <10 rows out of the millions in it. This issue would cause an entire transaction to abort after 45 minutes.
Our initial solution was not scalable, so we re-engineered our process to clone each database into Postgres first. Since we had a direct 1-1 schema mapping, we had to obey the constraints in the source database. This meant starting with tables with no foreign key dependencies and working backwards. This approach allowed us to identify and fix character set issues in an isolated transaction, without losing previous work.
We also had to manipulate the primary keys to match the foreign constraints, which is a common task in database migrations.
Phase 3 – Database Convergence
At this stage, we had three separate databases with 100% data clones. Since Experience.Digital was also doing the application rebuild, this was a modelling activity.
SQLAlchemy was an invaluable tool for this work. Although it required more upfront effort than other tools, the standardised operating environment allowed us to quickly develop a solution once the boilerplate was done. The standardised representation in a Python REPL allowed us to quickly identify and live-test conversion issues. This was especially helpful when troubleshooting issues with large batches of data.
Temporal Mapping
The other major component of this work entailed creating a version-control system in the database. The constraints added were:
- A timestamped version of every record in the database
- Temporally contiguous time range for updates (ie no holes)
Instead of implementing this in the application code, we implemented it in the database. Many people treat databases as just a storage layer with some validators, but we recognize them as a complete system to be used. We leveraged triggers to implement this feature and created the following model:
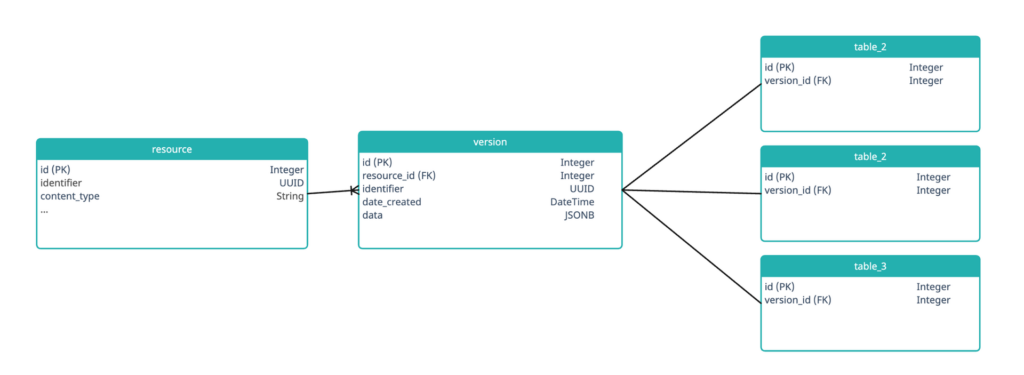
Every record in every table has a mandatory version_id foreign key, which in turn has an associated resource_id key. We wrote triggers to hook into the UPDATE and INSERT actions. When a record was updated or inserted, the triggers serialised the NEW representation to JSON using row_to_json() and wrote the record into a version table.
Writing the same 4 trigger functions for hundreds of tables is brittle and error-prone, so we leveraged the power of Python metaprogramming and the in-memory schema representation of SQLAlchemy to automatically generate and flush a CREATE TRIGGER clause for each trigger for each table.
Records could be deserialized back into the native Postgres record type by using the json_to_row() function. The ::<TYPE> cast on the function used internal Postgres reflection work to deserialize the contents to the correct Postgres record primitives.
This allowed a completely automated version control process to run, and allowed it to run independently of any application accessing it. Ensuring domain rules exist in their properly-bounded context is a design principle that we often see overlooked (often due to perceived complexity), but by using the correct tools, much richer outcomes can be achieved for only a minimally more upfront effort.